重新定义「小版本」!全面实测新版 DeepSeek R1,我们挖出了这些隐藏亮点
重新定义「小版本」!全面实测新版 DeepSeek R1,我们挖出了这些隐藏亮点DeepSeek 猝不及防地更新了,不是 R2,而是 R1 v2。
来自主题: AI资讯
9216 点击 2025-05-29 17:09
 搜索
搜索
DeepSeek 猝不及防地更新了,不是 R2,而是 R1 v2。
哈喽,大家好,我是袋鼠帝 昨天下午下班后,DeepSeek R1更新了 然而他们就只是悄悄在微信群里面发布了这个消息。

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……

在今年,DeepSeek R1火了之后。

英伟达官宣新办公室落户中国台湾省台北市,但居然是从太空飞下来的吗?

这组充满悬念的组合引发科技圈热议,业内普遍推测DeepSeek R2模型已进入发布倒计时。凤凰网科技从知情人士处获悉,目前网传信息的真实性含量很低。

原本的我:我把话撂这儿了,就是DeepSeek R2来了,我都不更!有事假期结束再说。 看完豆包Case的我:哎嘿真香~不是我卷朋友们,实在是它这波真的很强,非常强,4o在我这里暂时都没那么香了。废话咱就不多说了,还是先简介然后上案例!
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。

2025开年伊始,从1月DeepSeek R1发布引发新一轮国产大模型技术爆发,到3月Manus横空出世启动内测打开AI智能体话题热度,从底层基础设施到终端产品应用,从产业深耕提升纵深能力到产品创新形成差异化竞争优势,无论是技术能力还是商业模式,国产AI都处于全球领先水平。海外无论是政策环境还是供需关系,均从内外部双轮驱动国产AI出海蓄势待发。
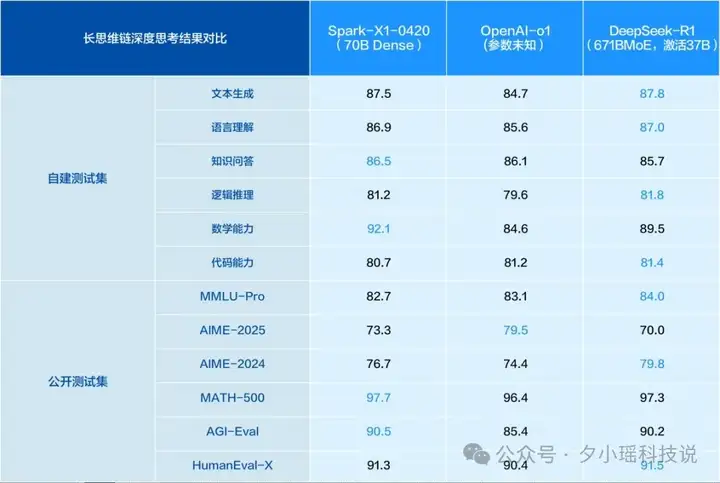
就在昨天,深耕语音、认知智能几十年的科大讯飞,发布了全新升级的讯飞星火推理模型 X1。不仅效果上比肩 DeepSeek-R1,而且我注意到一条官方发布的信息——基于全国产算力训练,在模型参数量比业界同类模型小一个数量级的情况下,整体效果能对标 OpenAI o1 和 DeepSeek R1。